Introduction: Python background
Overview
Teaching: 20 min
Exercises: 5 minQuestions
How much Python do we need to know?
What is “array-oriented” or “columnar” processing?
What is a “software ecosystem”?
Objectives
Get the background context to get started with the Uproot lessons.
How much Python do we need to know?
Basic Python
Most students start this module after a Python introduction or are already familiar with the basics of Python. For instance, you should be comfortable with the Python essentials such as assigning variables,
x = 5
if-statements,
if x < 5:
print("small")
else:
print("big")
and loops.
for i in range(x):
print(i)
Your data analysis will likely be full of statements like these, though the kinds of operations we’ll be focusing on in this module have a form more like
import compiled_library
compiled_library.do_computationally_expensive_thing(big_array)
The trick is for the Python-side code to be expressive enough and the compiled code to be general enough that you don’t need a new compiled_library for each thing you want to do. The libraries presented in this module are designed with interfaces that let you express what you want to do in Python and have it run in compiled code.
Dict-like and array-like interfaces
The two most important data types for these interfaces are dicts
some_dict = {"word": 1, "another word": 2, "some other word": 3}
some_dict["some other word"]
for key in some_dict:
print(key, some_dict[key])
and arrays
import numpy as np
some_array = np.array([0.0, 1.1, 2.2, 3.3, 4.4, 5.5, 6.6, 7.7, 8.8, 9.9])
some_array[4]
for x in some_array:
print(x)
Although these data types are important, what’s more important is the interfaces to these types. They both represent functions from keys to values:
- dicts (usually) map from strings to Python objects,
- arrays (always) map from non-negative integers to numerical values.
Most of the types we will see in this module also map strings or integers to data, and they use the same syntax as dicts and arrays. If you’re familiar with the dict and array interfaces, you usually won’t have to look up documentation on dict-like and array-like types unless you’re trying to do something special.
Review of the dict interface
For dicts, the things that can go in square brackets (its “domain,” as a function) are its keys.
some_dict = {"word": 1, "another word": 2, "some other word": 3}
some_dict.keys()
Nothing other than these keys can be used in square brackets
some_dict["something I made up"]
unless it has been added to the dict.
some_dict["something I made up"] = 123
some_dict["something I made up"]
The things that can come out of a dict (its “range,” as a function) are its values.
some_dict.values()
You can get keys and values as 2-tuples by asking for its items.
some_dict.items()
for key, value in some_dict.items():
print(key, value)
Review of the array interface
For arrays, the things that can go in square brackets (its “domain,” as a function) are integers from zero up to but not including its length.
import numpy as np
some_array = np.array([0.0, 1.1, 2.2, 3.3, 4.4, 5.5, 6.6, 7.7, 8.8, 9.9])
some_array[0] # okay
some_array[1] # okay
some_array[9] # okay
some_array[10] # not okay
You can get the length of an array (and the number of keys in a dict) with len:
len(some_array)
It’s important to remember that index 0 corresponds to the first item in the array, 1 to the second, and so on, which is why len(some_array) is not a valid index.
Negative indexes are allowed, but they count from the end of the list to the beginning. For instance,
some_array[-1]
returns the last item. Quick quiz: which negative value returns the first item, equivalent to 0?
Arrays can also be “sliced” by putting a colon (:) between the starting and stopping index.
some_array[2:7]
Quick quiz: why is 7.7 not included in the output?
The above is common to all Python sequences. Arrays, however, can be multidimensional and this allows for more kinds of slicing.
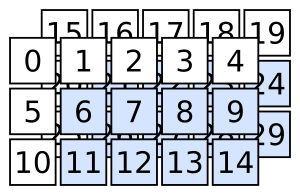
array3d = np.arange(2 * 3 * 5).reshape(2, 3, 5)
Separating two slices in the square brackets with a comma
array3d[:, 1:, 1:]
selects the following:
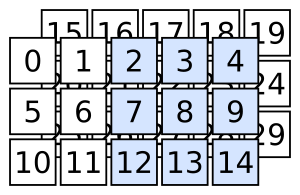
Quick quiz: how do you select the following?
Filtering with booleans and integers: “cuts”
In addition to integers and slices, arrays can be included in the square brackets.
An array of booleans with the same length as the sliced array selects all items that line up with True.
some_array = np.array([0.0, 1.1, 2.2, 3.3, 4.4, 5.5, 6.6, 7.7, 8.8, 9.9])
boolean_array = np.array(
[True, True, True, True, True, False, True, False, True, False]
)
some_array[boolean_array]
An array of integers selects items by index.
some_array = np.array([0.0, 1.1, 2.2, 3.3, 4.4, 5.5, 6.6, 7.7, 8.8, 9.9])
integer_array = np.array([0, 1, 2, 3, 4, 6, 8])
some_array[integer_array]
Integer-slicing is more general than boolean-slicing because an array of integers can also change the order of the data and repeat items.
some_array[np.array([4, 2, 2, 2, 9, 8, 3])]
Both come up in natural contexts. Boolean arrays often come from performing a calculation on all elements of an array that returns boolean values.
even_valued_items = some_array * 10 % 2 == 0
some_array[even_valued_items]
This is how we’ll be computing and applying cuts: expressions like
good_muon_cut = (muons.pt > 10) & (abs(muons.eta) < 2.4)
good_muons = muons[good_muon_cut]
Logical operators: &, |, ~, and parentheses
If you’re coming from C++, you might expect “and,” “or,” “not” to be &&, ||, !.
If you’re coming from non-array Python, you might expect them to be and, or, not.
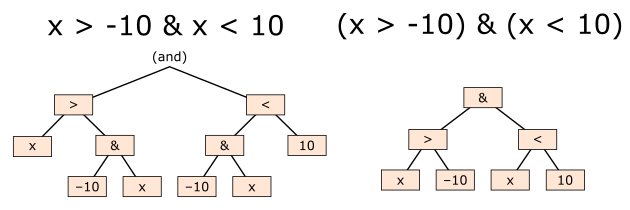
In array expressions (unfortunately!), we have to use Python’s bitwise operators, &, |, ~, and ensure that comparisons are surrounded in parentheses. Python’s and, or, not are not applied across arrays and bitwise operators have a surprising operator-precedence.
x = 0
x > -10 & x < 10 # probably not what you expect!
(x > -10) & (x < 10)
What is “array-oriented” or “columnar” processing?
Expressions like
even_valued_items = some_array * 10 % 2 == 0
perform the *, %, and == operations on every item of some_array and return arrays. Without NumPy, the above would have to be written as
even_valued_items = []
for x in some_array:
even_valued_items.append(x * 10 % 2 == 0)
This is more cumbersome when you want to apply a mathematical formula to every item of a collection, but it is also considerably slower. Every step in a Python for loop performs sanity checks that are unnecessary for numerical values with uniform type, checks that would happen at compile-time in a compiled library. NumPy is a compiled library; its *, %, and == operators, as well as many other functions, are performed in fast, compiled loops.
This is how we get expressiveness and speed. Languages with operators that apply array at a time, rather than one scalar value at a time, are called “array-oriented” or “columnar” (referring to, for instance, Pandas DataFrame columns).
Quite a few interactive, data-analysis languages are array-oriented, deriving from the original APL. “Array-oriented” is a programming paradigm in the same sense as “functional” or “object-oriented.”
What is a “software ecosystem”?
Some programming environments, like Mathematica, Emacs, and ROOT, attempt to provide you with everything you need in one package. There’s only one thing to install and components within the framework should work well together because they were developed together. However, it can be hard to use the framework with other, unrelated software packages.
Ecosystems, like UNIX, iOS App Store, and Python, consist of many small software packages that each do one thing and know how to communicate with other packages through conventions and protocols. There’s usually a centralized installation mechanism, and it is the user’s (your) responsibility to piece together what you need. However, the set of possibilities is open-ended and grows as needs develop.
In mainstream Python, this means that
- NumPy only deals with arrays,
- Pandas only deals with tables,
- Matplotlib only plots,
- Jupyter only provides a notebook interface,
- Scikit-Learn only does machine learning,
- h5py only interfaces with HDF5 files,
- etc.
Python packages for high-energy physics are being developed with a similar model:
- Uproot only reads and writes ROOT files,
- Awkward Array only deals with arrays of irregular types,
- hist only deals with histograms,
- iminuit only optimizes,
- zfit only fits,
- Particle only provides PDG-style data,
- etc.
To make things easier to find, they’re cataloged under a common name at scikit-hep.org.

Key Points
Be familiar with the syntax of Python dicts, NumPy arrays, slicing rules, and bitwise logic operators.
Large-scale computations in Python tend to be performed one array at a time, rather than one scalar operation at a time.
You, as a user, will likely be gluing together many packages in each data analysis.