Goodness of fit metrics#
So far, we’ve mostly been fitting datasets with small numbers of dimensions and identifying good or bad fits by eye.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
Ansatz fitting (traditional HEP)#
When fitting data with a parameterized functional form, traditional HEP analyses would check that the reduced \(\chi^2\),
is close to 1. The \(N_{\mbox{dof}}\), number of degrees of freedom, is the number of data points \(N\) minus the number of parameters in the ansatz. This \(\chi^2\) is the regression loss function evaluated on training data, and using \(N_{\mbox{dof}}\) as the denominator adjusts for the bias that is introduced by judging the fit by how well it performs on training data. Anyway, the number of parameters in the ansatz is always much less than \(N\), so overfitting is unlikely.
The “close to 1” criterion can be a little more formal by instead computing the \(\chi^2\) probability as \(P(\chi^2, N_{\mbox{dof}})\) from
which is available in SciPy as scipy.stats.chi2. This probability, when computed for many similar fits, should be nearly uniform between \(0\) and \(1\), so values that are very close to \(0\) are likely underfitted and values that are very close to \(1\) are likely overfitted.
The loss function#
For many-parameter ML fits, we need to be more careful about overfitting. In fact, overfitting is the usual case, since the easy way to produce an optimal model is to give it too many parameters and restrict them with regularization.
As we’ve seen, evaluating the loss function for the training data and the validation data, both as a function of epoch, reveals overfitting by a divergence between these two curves. Usually, the validation loss levels out (overfitting to the training data doesn’t help the model generalize), but in principle, overfitting could make the validation loss get worse with epoch.

For regression problems, you can also look at the raw residuals,
or pulls, which are weighted by uncertainties \(\sigma_{y_i}\),
their mean (the “bias” of the model) and standard deviation (the “resolution” of the model). All of these, however, are components of the \(\chi^2\) (for a weighted regression in the case of pulls). It can be useful to break this down, rather than only looking at the \(\chi^2 / N_{\mbox{dof}}\) as a summary, but they’re all parts of the same thing.
For classification problems, there’s another suite of goodness-of-fit measures we can consider.
Confusion matrix#
Story time:
Once upon a time, a shepherd boy got bored while tending the village’s sheep. For fun, he cried, “Wolf!” even though there was no wolf. The villagers ran to protect the sheep, then got mad when they saw that there was no wolf.
The next day, the same thing happened.
The day after that, there actually was a wolf and the shepherd cried, “Wolf!” but the villagers refused to be fooled again and didn’t help. The wolf ate all the sheep.
Each day, there are two possible truth states:
there actually is a wolf
there is not wolf
and two possible claims by a model that puports to represent reality (the shepherd boy’s utterances):
he cries, “Wolf!”
he does not cry, “Wolf!”
Together, they make four combinations, collectively called the confusion matrix:
| there is a wolf | there is no wolf | |||
| he cries, "Wolf!" |  true positive |
 false positive |
||
| he does not cry, "Wolf!" |  false negative |
 true negative |
It’s easy to get the terminology confused: “positive” and “negative” represent what the model says, like the result of a medical test. “True” and “false” specifies whether that test accords with reality or not.
For a concrete example, let’s make a linear model that separates orange and blue points in an \(x\)-\(y\) plane:
from sklearn.linear_model import LogisticRegression
all_target = np.random.randint(0, 2, 200)
all_xy = np.random.normal(-0.5, 0.75, (len(all_target), 2))
all_xy[all_target == 1] = np.random.normal(0.5, 0.75, (np.count_nonzero(all_target), 2))
model = LogisticRegression().fit(all_xy, all_target)
fig, ax = plt.subplots(figsize=(5, 5))
def plot_cutoff_decision_at(threshold):
# compute the three probabilities for every 2D point in the background
background_x, background_y = np.meshgrid(np.linspace(-3, 3, 100), np.linspace(-3, 3, 100))
background_2d = np.column_stack([background_x.ravel(), background_y.ravel()])
probabilities = model.predict_proba(background_2d)
# draw contour lines where the probabilities cross the 50% threshold
ax.contour(background_x, background_y, probabilities[:, 1].reshape(background_x.shape), [threshold])
ax.contourf(background_x, background_y, probabilities[:, 1].reshape(background_x.shape), alpha=0.1)
# draw data points on top
ax.scatter(all_xy[all_target == 0, 0], all_xy[all_target == 0, 1])
ax.scatter(all_xy[all_target == 1, 0], all_xy[all_target == 1, 1])
ax.axis([-3, 3, -3, 3])
plot_cutoff_decision_at(0.5)
plt.show()
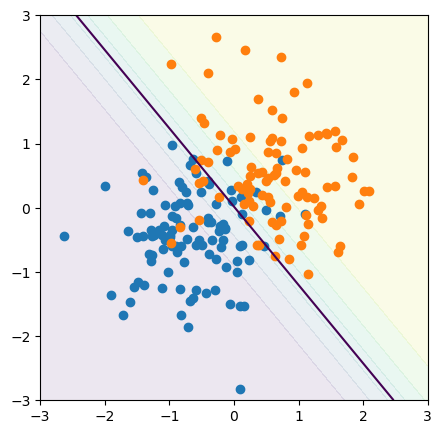
In the training data, we know which points are actually orange and actually blue:
actually_blue = all_xy[all_target == 0]
actually_orange = all_xy[all_target == 1]
And we can ask the model which points it says are blue, which we’ll label as the “positive” condition, and which are orange, which we’ll label as “negative.”
def model_says_blue(data_subset):
return np.sum(model.predict(data_subset) == 0)
def model_says_orange(data_subset):
return np.sum(model.predict(data_subset) == 1)
true_positive = model_says_blue(actually_blue)
false_positive = model_says_blue(actually_orange)
false_negative = model_says_orange(actually_blue)
true_negative = model_says_orange(actually_orange)
Here’s the confusion matrix as an array of counts:
confusion_matrix = np.array([
[true_positive, false_positive],
[false_negative, true_negative],
])
confusion_matrix
array([[94, 10],
[10, 86]])
And here it is as an array of fractions:
confusion_matrix / len(all_xy)
array([[0.47, 0.05],
[0.05, 0.43]])
This is a pretty good model because the diagonal (true positive and true negative) has large numbers, about 0.4, while the off-diagonal (false positive and false negative) has small numbers, about 0.1.
Also note that if you are using fractions, the sum of the matrix is \(1\) by construction:
np.sum(confusion_matrix / len(all_xy))
np.float64(1.0)
Quantities derived from the confusion matrix#
Many goodness-of-fit terms are derived from the binary (2×2) confusion matrix, and some of them have different names in different fields. Here’s a summary.
Accuracy: probability of getting the correct result from the model, whether positive or negative.
accuracy = (true_positive + true_negative) / len(all_xy)
accuracy
np.float64(0.9)
Sensitivity: probability of getting a positive result in cases that are actually positive.
In HEP, this is also called signal efficiency.
Yet another term: it’s also called recall and true positive rate.
sensitivity = true_positive / (true_positive + false_negative)
sensitivity
np.float64(0.9038461538461539)
Specificity: probability of getting a negative result in cases that are actually negative.
specificity = true_negative / (true_negative + false_positive)
specificity
np.float64(0.8958333333333334)
In HEP, there’s also background efficiency, which is the false positive rate.
background_efficiency = false_positive / (true_negative + false_positive)
background_efficiency
np.float64(0.10416666666666667)
and its reciprocal, background rejection.
background_rejection = 1/background_efficiency
background_rejection
np.float64(9.6)
Here are some less-used terms:
Precision: probability that a case is actually positive when the model says so.
precision = true_positive / (true_positive + false_positive)
precision
np.float64(0.9038461538461539)
F₁ score: harmonic mean of precision and recall.
f1_score = 2 / (1/precision + 1/sensitivity)
f1_score
np.float64(0.9038461538461539)
The F₁ score ranges from 0 (worst) to 1 (best), and there is a family of Fᵦ scores, defined with different weights.
ROC curve#
Returning to the Boy Who Cried Wolf, the 4 outcomes are not equally good or bad. Public scorn is not as bad as all the sheep being eaten, so if the shepherd boy has any doubt about whether a wolf-like animal is actually a wolf, he should err on the side of calling it a wolf.
Suppose that we want to catch as many blue (positive) points as possible, and we’re willing to accept some contamination of orange (negative). Instead of cutting the model at its 50% threshold, perhaps we should cut it at its 90% threshold:
fig, ax = plt.subplots(figsize=(5, 5))
plot_cutoff_decision_at(0.9)
plt.show()
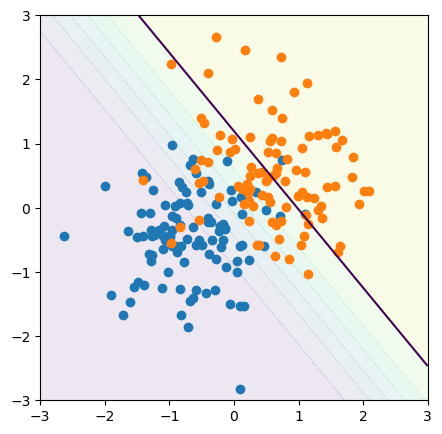
Similarly, we can get a confusion matrix for this looser threshold:
def matrix_for_cutoff_decision_at(threshold):
actually_blue = all_xy[all_target == 0]
actually_orange = all_xy[all_target == 1]
def model_says_blue(data_subset):
return np.sum(model.predict_proba(data_subset)[:, 0] > threshold)
def model_says_orange(data_subset):
return np.sum(model.predict_proba(data_subset)[:, 0] <= threshold)
true_positive = model_says_blue(actually_blue)
false_positive = model_says_blue(actually_orange)
false_negative = model_says_orange(actually_blue)
true_negative = model_says_orange(actually_orange)
return np.array([
[true_positive, false_positive],
[false_negative, true_negative],
])
A loose 90% threshold allows more false negatives (bottom left) in order to reduce the false positives (top right):
matrix_for_cutoff_decision_at(0.9) / len(all_xy)
array([[0.295, 0.015],
[0.225, 0.465]])
A tight 10% threshold allows more false positives (top right) in order to reduce the false negatives (bottom left):
matrix_for_cutoff_decision_at(0.1) / len(all_xy)
array([[0.51 , 0.245],
[0.01 , 0.235]])
With just two categories, the sum of this matrix is still 1, for any threshold.
np.sum(matrix_for_cutoff_decision_at(0.1) / len(all_xy))
np.float64(1.0)
To summarize all of this in one plot, we can vary the threshold from 0% to 100% and plot the true positive rates versus the false positive rates. This is called a Receiver Operating Characteristic (ROC) curve for historical reasons.
true_positive_rates = []
false_positive_rates = []
for threshold in np.linspace(0, 1, 1000):
((true_positive, false_positive),
(false_negative, true_negative)) = matrix_for_cutoff_decision_at(threshold)
true_positive_rates.append(true_positive / (true_positive + false_negative))
false_positive_rates.append(false_positive / (true_negative + false_positive))
fig, ax = plt.subplots(figsize=(5, 5))
ax.plot(false_positive_rates, true_positive_rates)
ax.grid(True, linestyle=":")
ax.set_xlabel("false positive rate")
ax.set_ylabel("true positive rate")
plt.show()
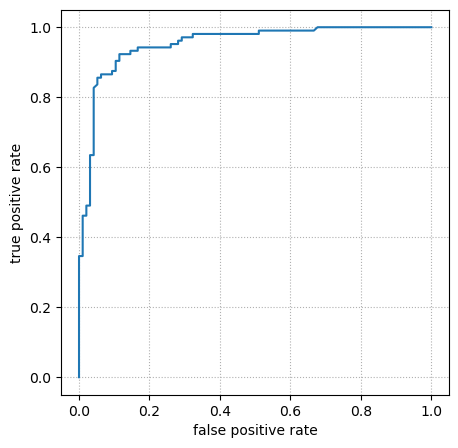
Some properties of the ROC curve:
It has endpoints at \((0, 0)\), the tightest threshold that doesn’t recognize any inputs as “positive,” and at \((1, 1)\), the loosest threshold that recognizes all inputs as “positive.”
The better a model is, the closer it gets to \((0, 1)\) (zero false positive rate and perfect true positive rate).
If the model is completely uninformative—randomly guessing—then the ROC curve is a horizontal line from \((0, 0)\) to \((1, 1)\). (For finite datasets, it’s a noisy horizontal line: it only approaches a perfect diagonal when evaluated on very large datasets.)
If you plot the ROC curve with higher resolution than the size of the dataset it is evaluated on, as above, it consists of horizontal and vertical segments as the threshold curve scans across individual points (of the two categories).
Be sure to plot the ROC curve using the validation dataset while tuning hyperparameters and only use the test dataset after the model is fixed.
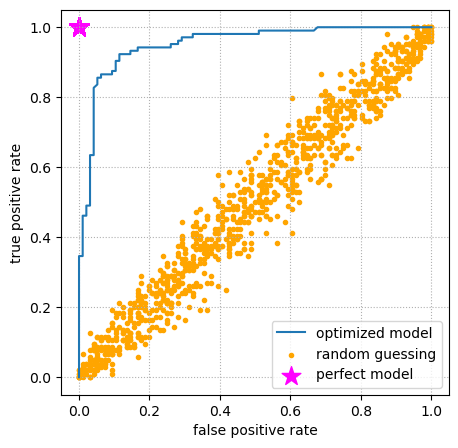
For completeness, let’s see the ROC curves for a perfect model (always correct) and a model that randomly guesses.
def matrix_for_perfect_model(threshold):
actually_blue = all_xy[all_target == 0]
actually_orange = all_xy[all_target == 1]
true_positive = len(actually_blue)
false_negative = 0
true_negative = len(actually_orange)
false_positive = 0
return np.array([
[true_positive, false_positive],
[false_negative, true_negative],
])
def matrix_for_random_model(threshold):
actually_blue = all_xy[all_target == 0]
actually_orange = all_xy[all_target == 1]
true_positive = np.sum(np.random.uniform(0, 1, len(actually_blue)) > threshold)
false_negative = len(actually_blue) - true_positive
true_negative = np.sum(np.random.uniform(0, 1, len(actually_orange)) <= threshold)
false_positive = len(actually_orange) - true_negative
return np.array([
[true_positive, false_positive],
[false_negative, true_negative],
])
perfect_true_positive_rates = []
perfect_false_positive_rates = []
for threshold in np.linspace(0, 1, 1000):
((true_positive, false_positive),
(false_negative, true_negative)) = matrix_for_perfect_model(threshold)
perfect_true_positive_rates.append(true_positive / (true_positive + false_negative))
perfect_false_positive_rates.append(false_positive / (true_negative + false_positive))
random_true_positive_rates = []
random_false_positive_rates = []
for threshold in np.linspace(0, 1, 1000):
((true_positive, false_positive),
(false_negative, true_negative)) = matrix_for_random_model(threshold)
random_true_positive_rates.append(true_positive / (true_positive + false_negative))
random_false_positive_rates.append(false_positive / (true_negative + false_positive))
fig, ax = plt.subplots(figsize=(5, 5))
ax.plot(false_positive_rates, true_positive_rates)
ax.scatter(random_false_positive_rates, random_true_positive_rates, marker=".", color="orange")
ax.scatter(perfect_false_positive_rates, perfect_true_positive_rates, s=200, marker="*", color="magenta")
ax.grid(True, linestyle=":")
ax.set_xlabel("false positive rate")
ax.set_ylabel("true positive rate")
ax.legend(["optimized model", "random guessing", "perfect model"])
plt.show()
In HEP analyses, it’s usually more important to exclude background events than to accept signal, since we’re usually interested in extremely rare processes. Therefore, ROC curves are plotted differently, often employing logarithmic axes and background rejection, the reciprocal of false positive rate. Here is an example that compares the quality of several models for identifying \(b\)-jets (“\(b\)-jet tagging efficiency” is true positive rate, so the axes are also swapped):
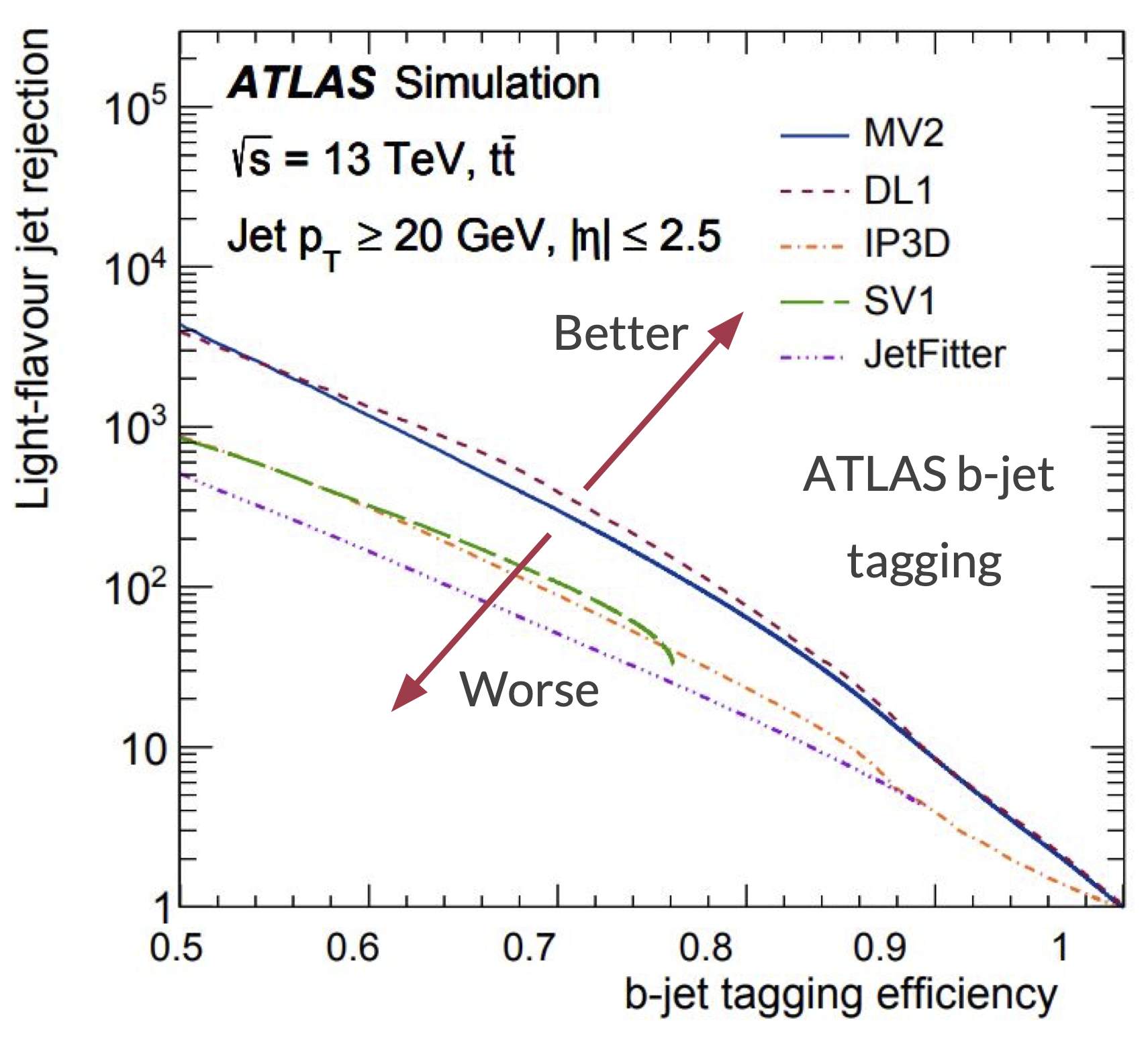
Area under the ROC curve#
The ROC curve summarizes the tradeoff between accepting more signal and rejecting more background on a single plot. But can we get it in a single number?
On a plane in which ROC curves that reach higher are better, the Area Under the Curve (AUC) is higher for good models and lower for bad models:
A perfect model has an AUC of exactly \(1\). Here’s how our optimized model fares:
sorted_indexes = np.argsort(false_positive_rates)
sorted_x = np.array(false_positive_rates)[sorted_indexes]
sorted_y = np.array(true_positive_rates)[sorted_indexes]
np.trapz(sorted_y, sorted_x, 0.001)
/tmp/ipykernel_2554/2935540138.py:5: DeprecationWarning: `trapz` is deprecated. Use `trapezoid` instead, or one of the numerical integration functions in `scipy.integrate`.
np.trapz(sorted_y, sorted_x, 0.001)
np.float64(0.9506209935897436)
A randomly guessing model should be close to \(0.5\) (exactly \(0.5\) in the limit of infinitely large datasets):
sorted_indexes = np.argsort(random_false_positive_rates)
sorted_x = np.array(random_false_positive_rates)[sorted_indexes]
sorted_y = np.array(random_true_positive_rates)[sorted_indexes]
np.trapz(sorted_y, sorted_x, 0.001)
/tmp/ipykernel_2554/2279154368.py:5: DeprecationWarning: `trapz` is deprecated. Use `trapezoid` instead, or one of the numerical integration functions in `scipy.integrate`.
np.trapz(sorted_y, sorted_x, 0.001)
np.float64(0.5018028846153847)
More than two categories#
With \(n\) categories, our confusion matrix becomes \(n \times n\), since the model can report any category \(c_i\) for any actual category \(c_j\). As before, a good model has large numbers on the diagonal (reported category is the actual category).
Let’s see this with our penguins.
penguins_df = pd.read_csv("data/penguins.csv")
categorical_int_df = penguins_df.dropna()[["bill_length_mm", "bill_depth_mm", "species"]]
categorical_int_df["species"], code_to_name = pd.factorize(categorical_int_df["species"].values)
# Pre-normalize the data so we can ignore that part of modeling
feats = ["bill_length_mm", "bill_depth_mm"]
categorical_int_df[feats] = (
categorical_int_df[feats] - categorical_int_df[feats].mean()
) / categorical_int_df[feats].std()
features = categorical_int_df[feats].values
targets = categorical_int_df["species"].values
from sklearn.linear_model import LogisticRegression
best_fit = LogisticRegression(penalty=None).fit(features, targets)
fig, ax = plt.subplots(figsize=(5, 5))
# compute the three probabilities for every 2D point in the background
background_x, background_y = np.meshgrid(np.linspace(-3, 3, 100), np.linspace(-3, 3, 100))
background_2d = np.column_stack([background_x.ravel(), background_y.ravel()])
probabilities = best_fit.predict_proba(background_2d)
# draw contour lines where the probabilities cross the 50% threshold
ax.contour(background_x, background_y, probabilities[:, 0].reshape(background_x.shape), [0.5])
ax.contour(background_x, background_y, probabilities[:, 1].reshape(background_x.shape), [0.5])
ax.contour(background_x, background_y, probabilities[:, 2].reshape(background_x.shape), [0.5])
ax.scatter(features[targets == 0, 0], features[targets == 0, 1])
ax.scatter(features[targets == 1, 0], features[targets == 1, 1])
ax.scatter(features[targets == 2, 0], features[targets == 2, 1])
ax.set_xlim(-3, 3)
ax.set_ylim(-3, 3)
ax.set_xlabel("scaled bill length (unitless)")
ax.set_ylabel("scaled bill depth (unitless)")
plt.show()
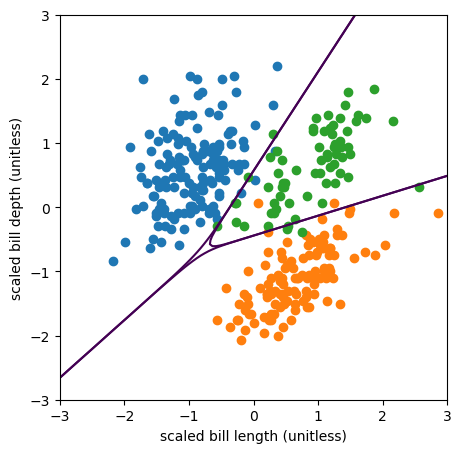
Now the model is 3×3.
def matrix_for_penguins(threshold):
actually_Adelie = features[targets == 0]
actually_Gentoo = features[targets == 1]
actually_Chinstrap = features[targets == 2]
def model_says_Adelie(data_subset):
return np.sum(best_fit.predict_proba(data_subset)[:, 0] > threshold)
def model_says_Gentoo(data_subset):
return np.sum(best_fit.predict_proba(data_subset)[:, 1] > threshold)
def model_says_Chinstrap(data_subset):
return np.sum(best_fit.predict_proba(data_subset)[:, 2] > threshold)
return np.array([
[model_says_Adelie(actually_Adelie), model_says_Adelie(actually_Gentoo), model_says_Adelie(actually_Chinstrap)],
[model_says_Gentoo(actually_Adelie), model_says_Gentoo(actually_Gentoo), model_says_Gentoo(actually_Chinstrap)],
[model_says_Chinstrap(actually_Adelie), model_says_Chinstrap(actually_Gentoo), model_says_Chinstrap(actually_Chinstrap)],
])
matrix_for_penguins(0.5)
array([[143, 0, 3],
[ 0, 117, 4],
[ 3, 2, 61]])
Since this is a good model, the diagonals are much larger than the off-diagonals.
The matrix also has a fractional form,
matrix_for_penguins(0.5) / len(features)
array([[0.42942943, 0. , 0.00900901],
[0. , 0.35135135, 0.01201201],
[0.00900901, 0.00600601, 0.18318318]])
but the sum is not always \(1\):
np.sum(matrix_for_penguins(0.99) / len(features))
np.float64(0.7867867867867867)
We can’t plot this as a ROC curve, since each of the categories extends in a different dimension. (It would be a “ROC surface” in \(n\) dimensions.)
Not all of the quantities in the suite of definitions are still meaningful with multiple categories, but a few are.
[[AA, AG, AC],
[GA, GG, GC],
[CA, CG, CC]] = matrix_for_penguins(0.5)
Accuracy is a sum along the diagonal:
accuracy = (AA + GG + CC) / len(features)
accuracy
np.float64(0.963963963963964)
Each category has its own sensitivity and specificity:
sensitivity_A = AA / (AA + GA + CA)
sensitivity_G = GG / (AG + GG + CG)
sensitivity_C = CC / (AC + GC + CC)
sensitivity_A, sensitivity_G, sensitivity_C
(np.float64(0.9794520547945206),
np.float64(0.9831932773109243),
np.float64(0.8970588235294118))
specificity_A = (GG + GC + CG + CC) / (AG + AC + GG + GC + CG + CC)
specificity_G = (AA + AC + CA + CC) / (GA + GC + AA + AC + CA + CC)
specificity_C = (AA + AG + GA + GG) / (CA + CG + AA + AG + GA + GG)
specificity_A, specificity_G, specificity_C
(np.float64(0.983957219251337),
np.float64(0.9813084112149533),
np.float64(0.9811320754716981))
But that’s because, for each category, we’re labeling that category as “positive” and all the other categories as “negative” to compute the binary sensitivity and specificity. In general, we can always label a subset of the categories as positive and the rest as negative to use binary classification goodness-of-fit criteria, including ROC curves.
Now you have everything that you need to do the main project.