Introducción: Fundamentos de Python#
¿Cuánto Python necesitamos saber?#
Python básico#
La mayoría de los estudiantes comienzan este módulo después de una introducción a Python o ya están familiarizados con los fundamentos de Python. Por ejemplo, deberías sentirte cómodo con lo esencial de Python, como asignar variables,
x = 5
sentencias if,
if x < 5:
print("pequeño")
else:
print("grande")
grande
y bucles.
for i in range(x):
print(i)
0
1
2
3
4
Tu análisis de datos probablemente estará lleno de declaraciones como estas, aunque los tipos de operaciones en las que nos enfocaremos en este módulo tendrán una forma más parecida a
import libreria_compilada
libreria_compilata.operacion_computacional_costosa(array_grande)
El truco está en que el código del lado de Python sea lo suficientemente expresivo y el código compilado lo suficientemente general para que no necesites una nueva libreria_compilada para cada cosa que quieras hacer. Las librería presentadas en este módulo están diseñadas con interfaces que te permiten expresar lo que quieres hacer en Python y ejecutarlo en código compilado.
Interfaces tipo diccionario y tipo array#
Los dos tipos de datos más importantes para estas interfaces son los diccionarios
un_diccionario = {"palabra": 1, "otra palabra": 2, "alguna otra palabra": 3}
un_diccionario["alguna otra palabra"]
3
for clave in un_diccionario:
print(clave, un_diccionario[clave])
palabra 1
otra palabra 2
alguna otra palabra 3
y los arrays
import numpy as np
un_array = np.array([0.0, 1.1, 2.2, 3.3, 4.4, 5.5, 6.6, 7.7, 8.8, 9.9])
un_array[4]
np.float64(4.4)
for x in un_array:
print(x)
0.0
1.1
2.2
3.3
4.4
5.5
6.6
7.7
8.8
9.9
Aunque estos tipos de datos son importantes, lo que es más importante son las interfaces de estos tipos. Ambos representan funciones de claves a valores:
los diccionarios (usualmente) mapean de cadenas a objetos de Python,
los arrays (siempre) mapean de enteros no negativos a valores numéricos.
La mayoría de los tipos que veremos en este módulo también mapean cadenas o enteros a datos, y usan la misma sintaxis que los diccionarios y los arrays. Si estás familiarizado con las interfaces de diccionarios y arrays, generalmente no tendrás que consultar la documentación sobre tipos parecidos a diccionarios o arrays, a menos que estés tratando de hacer algo especial.
Repaso de la interfaz de diccionario#
Para los diccionarios, las cosas que pueden ir entre corchetes (su “dominio,” como una función) son sus claves (keys).
un_diccionario = {"palabra": 1, "otra palabra": 2, "alguna otra palabra": 3}
un_diccionario.keys()
dict_keys(['palabra', 'otra palabra', 'alguna otra palabra'])
Nada más que estas claves puede usarse entre corchetes.
un_diccionario["algo que inventé"]
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[11], line 1
----> 1 un_diccionario["algo que inventé"]
KeyError: 'algo que inventé'
a menos que haya sido agregado al diccionario.
un_diccionario["algo que inventé"] = 123
un_diccionario["algo que inventé"]
123
Los elementos que pueden salir de un diccionario (su “rango,” como una función) son sus valores (values).
un_diccionario.values()
dict_values([1, 2, 3, 123])
Puedes obtener las claves y los valores como tuplas de 2 elementos al solicitar sus artículos (items).
un_diccionario.items()
dict_items([('palabra', 1), ('otra palabra', 2), ('alguna otra palabra', 3), ('algo que inventé', 123)])
for clave, valor in un_diccionario.items():
print(clave, valor)
palabra 1
otra palabra 2
alguna otra palabra 3
algo que inventé 123
Repaso de la interfaz de array#
Para los arrays, las cosas que pueden ir entre corchetes (su “dominio,” como una función) son enteros desde cero hasta, pero sin incluir, su longitud.
import numpy as np
un_array = np.array([0.0, 1.1, 2.2, 3.3, 4.4, 5.5, 6.6, 7.7, 8.8, 9.9])
un_array[0] # está bien
un_array[1] # está bien
un_array[9] # está bien
un_array[10] # no está bien
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
Cell In[16], line 7
5 un_array[1] # está bien
6 un_array[9] # está bien
----> 7 un_array[10] # no está bien
IndexError: index 10 is out of bounds for axis 0 with size 10
Puedes obtener la longitud de un array (y el número de claves en un diccionario) con len:
len(un_array)
10
Es importante recordar que el índice 0 corresponde al primer elemento del array, 1 al segundo, y así sucesivamente, por lo que len(some_array) no es un índice válido.
Se permiten índices negativos, pero cuentan desde el final de la lista hacia el principio. Por ejemplo,
un_array[-1]
np.float64(9.9)
devuelve el último elemento.
Quiz rápido: ¿qué valor negativo devuelve el primer elemento, equivalente a 0?
Los arrays también se pueden rebanar o partir colocando dos puntos (:) entre el índice inicial y el índice final.
un_array[2:7]
array([2.2, 3.3, 4.4, 5.5, 6.6])
Quiz rápido: ¿por qué 7.7 no está incluido?
Lo anterior es común a todas las secuencias de Python. Sin embargo, los arrays pueden ser multidimensionales y esto permite más tipos de rebanado.
array3d = np.arange(2 * 3 * 5).reshape(2, 3, 5)
Separando dos rebanadas en los corchetes con una coma
array3d[:, 1:, 1:]
array([[[ 6, 7, 8, 9],
[11, 12, 13, 14]],
[[21, 22, 23, 24],
[26, 27, 28, 29]]])
selecciona lo siguiente:
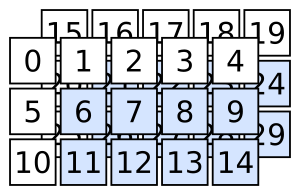
Quiz rápido: ¿cómo seleccionas lo siguiente?
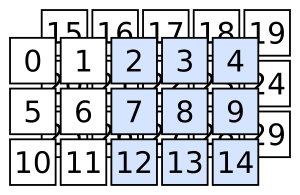
Filtrado con booleanos y enteros: “cortes”#
Además de enteros y rebanadas, los arrays pueden incluirse en los corchetes.
Un array de booleanos con la misma longitud que el array rebanado selecciona todos los elementos que coinciden con verdadero (True).
un_array = np.array([0.0, 1.1, 2.2, 3.3, 4.4, 5.5, 6.6, 7.7, 8.8, 9.9])
array_booleano = np.array(
[True, True, True, True, True, False, True, False, True, False]
)
un_array[array_booleano]
array([0. , 1.1, 2.2, 3.3, 4.4, 6.6, 8.8])
Un array de enteros selecciona elementos por índice.
un_array = np.array([0.0, 1.1, 2.2, 3.3, 4.4, 5.5, 6.6, 7.7, 8.8, 9.9])
array_de_enteros = np.array([0, 1, 2, 3, 4, 6, 8])
un_array[array_de_enteros]
array([0. , 1.1, 2.2, 3.3, 4.4, 6.6, 8.8])
El rebanado por enteros es más general que el rebanado booleano porque un array de enteros también puede cambiar el orden de los datos y repetir elementos.
un_array[np.array([4, 2, 2, 2, 9, 8, 3])]
array([4.4, 2.2, 2.2, 2.2, 9.9, 8.8, 3.3])
Ambos aparecen en contextos naturales. Los arrays booleanos a menudo provienen de realizar un cálculo en todos los elementos de un array que devuelve valores booleanos.
elementos_pares = un_array * 10 % 2 == 0
un_array[elementos_pares]
array([0. , 2.2, 4.4, 6.6, 8.8])
Así es como estaremos calculando y aplicando cortes: expresiones como
corte_muon_bueno = (muones.pt > 10) & (abs(muones.eta) < 2.4)
muones_buenos = muones[corte_muon_bueno]
Operadores lógicos: &, |, ~, y paréntesis#
Si vienes de C++, podrías esperar que “y,” “o,” “no” sean &&, ||, !.
Si vienes de Python no orientado a arrays, podrías esperar que sean and, or, not.
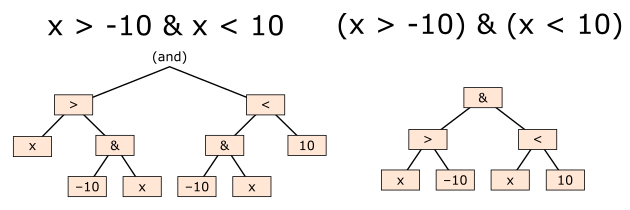
En las expresiones de arrays (¡desafortunadamente!), tenemos que usar los operadores bit a bit de Python, &, |, ~, y asegurarnos de que las comparaciones estén rodeadas de paréntesis. Los operadores and, or, not de Python no se aplican a través de arrays y los operadores bit a bit tienen una precedencia de operadores sorprendente.
x = 0
x > -10 & x < 10 # ¡probablemente no es lo que esperas!
False
(x > -10) & (x < 10)
True
¿Qué es el procesamiento “orientado a arrays” o “columnar”?#
Expresiones como
elementos_pares = un_array * 10 % 2 == 0
realizan las operaciones *, %, y == en cada elemento de un_array y devuelven arrays. Sin NumPy, lo anterior tendría que escribirse como
elementos_pares = []
for x in un_array:
elementos_pares.append(x * 10 % 2 == 0)
Esto es más engorroso cuando deseas aplicar una fórmula matemática a cada elemento de una colección, pero también es considerablemente más lento. Cada paso en un bucle for en Python realiza verificaciones de sanidad que son innecesarias para valores numéricos de tipo uniforme, verificaciones que se harían en tiempo de compilación en una librería compilada. NumPy es una librería compilada; sus operadores *, %, y ==, así como muchas otras funciones, se realizan en bucles rápidos y compilados.
Así es como obtenemos expresividad y velocidad. Los lenguajes con operadores que se aplican a arrays completos, en lugar de un valor escalar a la vez, se llaman lenguajes “orientados a arrays” o “columnares” (refiriéndose, por ejemplo, a las columnas de un DataFrame de Pandas).
Bastantes lenguajes interactivos de análisis de datos están orientados a arrays, derivando del APL original. “Orientado a arrays” es un paradigma de programación en el mismo sentido que “funcional” u “orientado a objetos”.
¿Qué es un “ecosistema de software”?#
Algunos entornos de programación, como Mathematica, Emacs y ROOT, intentan proporcionarte todo lo que necesitas en un solo paquete. Solo hay una cosa que instalar y los componentes dentro del marco deberían funcionar bien juntos porque se desarrollaron en conjunto. Sin embargo, puede ser difícil usar el marco con otros paquetes de software no relacionados.
Los ecosistemas, como UNIX, la App Store de iOS y Python, consisten en muchos paquetes de software pequeños que hacen una sola cosa y saben cómo comunicarse con otros paquetes a través de convenciones y protocolos. Por lo general, hay un mecanismo de instalación centralizado, y es responsabilidad del usuario reunir lo que se necesita. Sin embargo, el conjunto de posibilidades es abierto y crece a medida que surgen nuevas necesidades.
En el Python mainstream, esto significa que
NumPy solo maneja arrays,
Pandas solo maneja tablas,
Matplotlib solo genera gráficos,
Jupyter solo proporciona una interfaz de cuaderno,
Scikit-Learn solo hace aprendizaje automático,
h5py solo interactúa con archivos HDF5,
etc.
Los paquetes de Python para física de altas energías se están desarrollando con un modelo similar:
Uproot solo lee y escribe archivos ROOT,
Awkward Array solo maneja arrays de tipos irregulares,
hist solo maneja histogramas,
iminuit solo optimiza,
zfit solo ajusta,
Particle solo proporciona datos al estilo PDG,
etc.
Para facilitar su localización, están catalogados bajo un nombre común en scikit-hep.org.
