Run time comparisons
Overview
Teaching: 5 min
Exercises: 15 minQuestions
Will the ML performance of my model improve when I use the GPU?
Will the computational performance of my model improve when I use the GPU?
Objectives
Calculate the run time of GPU-enabled model training.
Perform a run-time comparison between CPU and GPU training.
In this lesson we will consider different ways of measuring performance and draw comparisons between training a model on the CPU and training it on the GPU.
Model performance
Just as in the Introduction to Machine Learning lesson you can evaluate the performance of your network using a variety of metrics. For example using
from sklearn.metrics import classification_report
print (classification_report(y_test, y_pred, target_names=["background", "signal"]))
However, remember that if you have made your predictions using the model on the GPU then you will need to move the prediction from your network y_pred off the GPU and onto the CPU before using the classification_report() function.
Challenge
Check the performance of the model you trained on the GPU and compare it to the same model trained on the CPU.
Solution
You shouldn’t see any difference in the performance of the two models.
Computational performance
Although there are different ways to evaluate the computational performance of your code, for the purpose of this tutorial the main metric that you’re probably interested in is run time. Training machine learning models can take a really long time and speeding this process up makes life much easier.
Calculating run time
An easy way to determine the run time for a particular section of code is to use the Python time library.
import time
mytime = time.time()
print(mytime)
The time.time() function returns the time in seconds since January 1, 1970, 00:00:00 (UTC). By itself it’s not always super useful, but for wrapping a piece of code and calculating the elapsed time between the start and end of that code it’s a nice and simple method for determining run time.
import time
start = time.time()
# insert some code to do something here
end = time.time()
print("Run time [s]: ",end-start)
Timing tests when using a GPU
When we are timing PyTorch processes that use a GPU it’s necessary to add one extra line of code into this loop:
import time
start = time.time()
# insert some code to do something here
if use_cuda: torch.cuda.synchronize() # <---------------- extra line
end = time.time()
print("Run time [s]: ",end-start)
This is because processes on a GPU run asynchronously. This means that when we send a process to the GPU it doesn’t necessarily run immediately, instead it joins a queue. By calling the torch.cuda.synchronize function before specifying the end of our timing test, we can ensure that all of the processes on the GPU have actually run before we calculate the run time.
Challenge
Calculate the run time for the GPU-enabled training loop in your code.
Solution
model = model.to(device) start = time.time() for batch, (x_train, y_train) in enumerate(train_loader): x_train, y_train = x_train.to(device), y_train.to(device) model.zero_grad() pred, prob = model(x_train) acc = (prob.argmax(dim=-1) == y_train).to(torch.float32).mean() train_accs.append(acc.mean().item()) loss = F.cross_entropy(pred, y_train) train_loss.append(loss.item()) loss.backward() optimizer.step() if use_cuda: torch.cuda.synchronize() end = time.time() print("Run time [s]: ",end-start)
Network depth
You’ll quickly realise that the GPU-enabled loop doesn’t really run that much faster than the normal training on CPU. That’s because the neural network we’ve been using so far is really really small so the matrix multiplications on the CPU are just as fast as the ones we can do on the GPU. The figure below shows how big our network needs to be to make the GPU useful by increasing the number of artificial neurons in each of our hidden layers.
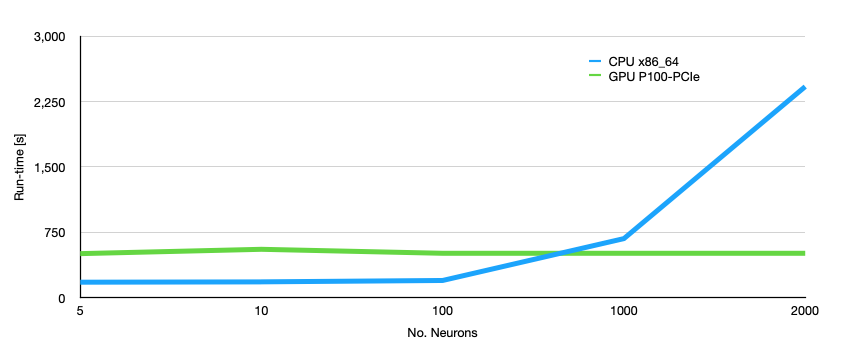
We can see from the above plot that for our small network with only two hidden layers we need at least 1000 neurons in each hidden layer to make using the GPU more useful than using the CPU. In fact for smaller networks the CPU is faster than the GPU. At this point you need to ask yourself: “how many neurons do I need?” The answer to this is of course specific to the application and it needs to be tuned using your validation data set. Then you can decide whether you need to run on GPU or not.
Challenge
Increase the number of neurons in the hidden layers of your network to 2000 and re-run your timing tests. How do the results look now?
Solution
hidden_size = 2000You should see a difference in run time that is roughly 4 - 5 x faster with the GPU. The exact value will depend on what type of GPU you are using.
Key Points
Using a GPU will not improve your ML performance.
Using a GPU will improve your run time only under certain circumstances.
GPU processes are asynchronous.