Histogram libraries¶
Mainstream Python has libraries for filling histograms.
NumPy¶
NumPy, for instance, has an np.histogram function.
import skhep_testdata, uproot
tree = uproot.open(skhep_testdata.data_path("uproot-Zmumu.root"))["events"]
import numpy as np
np.histogram(tree["M"].array())(<Array [172, 89, 29, 69, 277, 1640, 24, 0, 2, 2] type='10 * int64'>,
<Array [0.389, 17.6, 34.7, 51.9, ..., 121, 138, 155, 172] type='11 * float64'>)Because of NumPy’s prominence, this 2-tuple of arrays (bin contents and edges) is a widely recognized histogram format, though it lacks many of the features high-energy physicists expect (under/overflow, axis labels, uncertainties, etc.).
import matplotlib.pyplot as plt
plt.hist(tree["M"].array());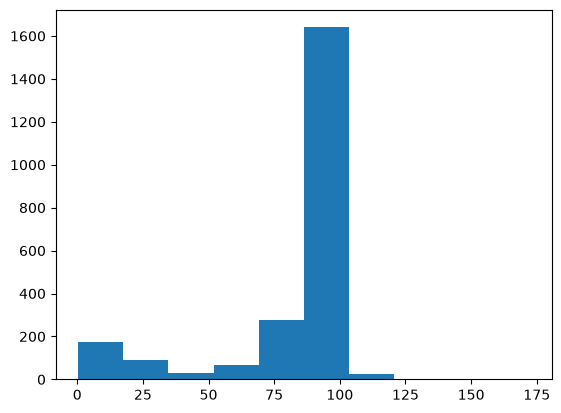
In addition to the same bin contents and edges as NumPy, Matplotlib includes a plottable graphic.
Boost-histogram and hist¶
The main feature that these functions lack (without some effort) is refillability. High-energy physicists usually want to fill histograms with more data than can fit in memory, which means setting bin intervals on an empty container and filling it in batches (sequentially or in parallel).
Boost-histogram is a library designed for that purpose. It is intended as an infrastructure component. You can explore its “low-level” functionality upon importing it:
import boost_histogram as bhA more user-friendly layer (with plotting, for instance) is provided by a library called “hist.”
import hist
h = hist.Hist(hist.axis.Regular(120, 60, 120, name="mass"))
h.fill(tree["M"].array())
h.plot();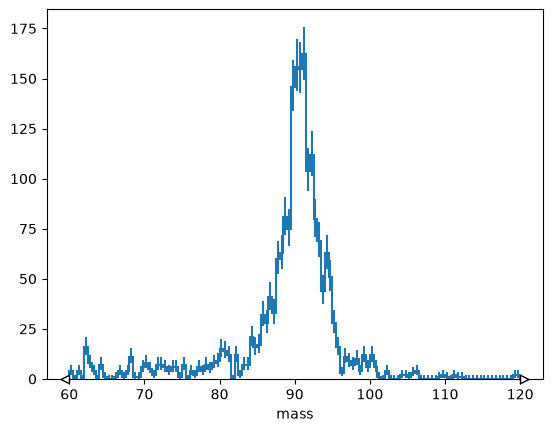
Universal Histogram Indexing (UHI)¶
There is an attempt within Scikit-HEP to standardize what array-like slices mean for a histogram. (See documentation.)
Naturally, integer slices should select a range of bins,
h[10:110].plot();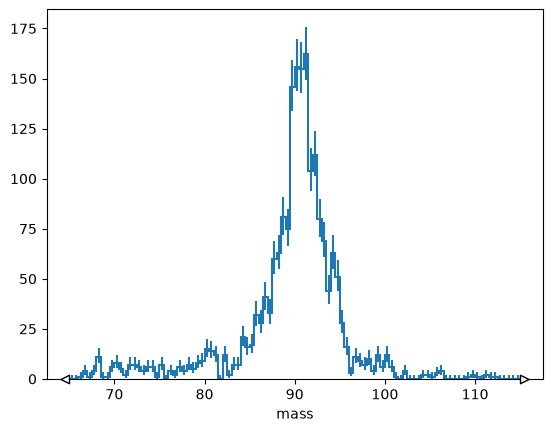
but often you want to select bins by coordinate value
# Explicit version
# h[hist.loc(90) :].plot();
# Short version
h[90j:].plot();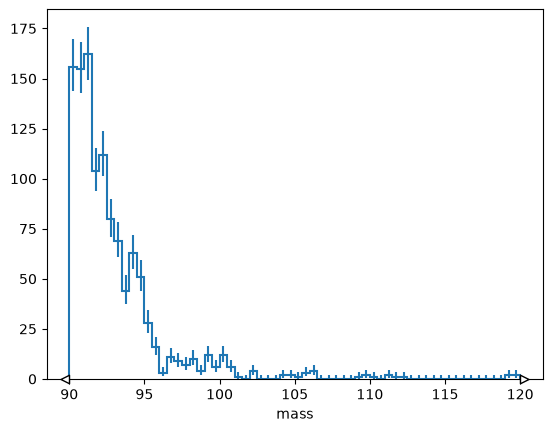
or rebin by a factor,
# Explicit version
# h[:: hist.rebin(2)].plot();
# Short version
h[::2j].plot();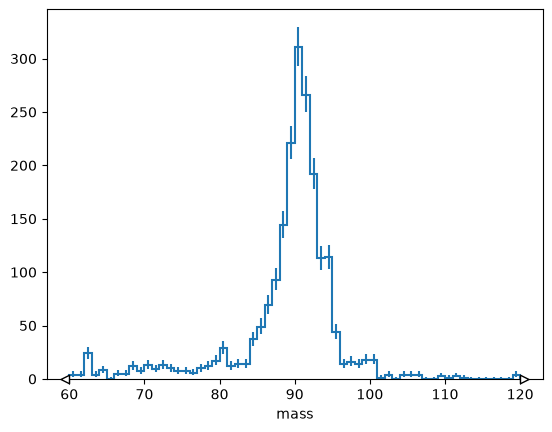
or sum over a range.
# Explicit version
# h[hist.loc(80) : hist.loc(100) : sum]
# Short version
h[90j:100j:sum]1102.0Things get more interesting when a histogram has multiple dimensions.
import uproot
import hist
import awkward as ak
picodst = uproot.open(
"https://pivarski-princeton.s3.amazonaws.com/pythia_ppZee_run17emb.picoDst.root:PicoDst"
)
vertexhist = hist.Hist(
hist.axis.Regular(600, -1, 1, label="x"),
hist.axis.Regular(600, -1, 1, label="y"),
hist.axis.Regular(40, -200, 200, label="z"),
)
vertex_data = picodst.arrays(filter_name="*mPrimaryVertex[XYZ]")
vertexhist.fill(
ak.flatten(vertex_data["Event.mPrimaryVertexX"]),
ak.flatten(vertex_data["Event.mPrimaryVertexY"]),
ak.flatten(vertex_data["Event.mPrimaryVertexZ"]),
)
vertexhist[:, :, sum].plot2d_full()
vertexhist[-0.25j:0.25j, -0.25j:0.25j, sum].plot2d_full()
vertexhist[sum, sum, :].plot()
vertexhist[-0.25j:0.25j:sum, -0.25j:0.25j:sum, :].plot();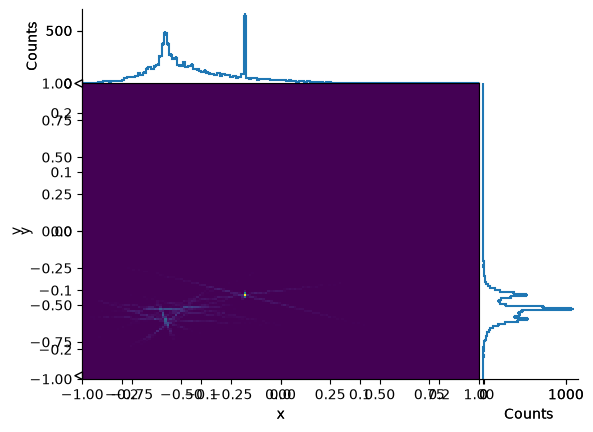
A histogram object can have more dimensions than you can reasonably visualize—you can slice, rebin, and project it into something visual later.
import numpy as np
import iminuit.cost
norm = len(h.axes[0].widths) / (h.axes[0].edges[-1] - h.axes[0].edges[0]) / h.sum()
def f(x, background, mu, gamma):
return (
background
+ (1 - background) * gamma**2 / ((x - mu) ** 2 + gamma**2) / np.pi / gamma
)
loss = iminuit.cost.LeastSquares(
h.axes[0].centers, h.values() * norm, np.sqrt(h.variances()) * norm, f
)
loss.mask = h.variances() > 0
minimizer = iminuit.Minuit(loss, background=0, mu=91, gamma=4)
minimizer.migrad()
minimizer.hesse()
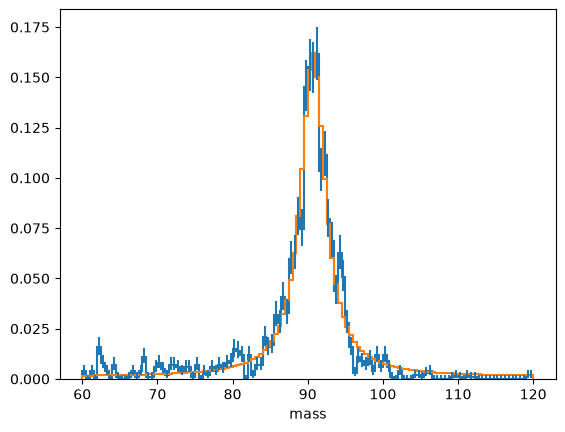
(h * norm).plot()
plt.plot(loss.x, f(loss.x, *minimizer.values));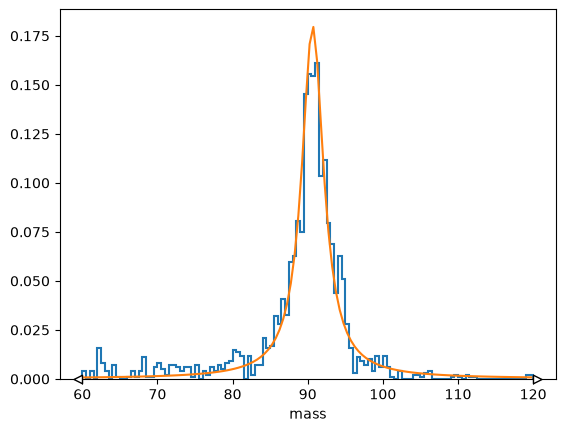
Or through zfit, a Pythonic RooFit-like fitter:
import zfit
binned_data = zfit.data.BinnedData.from_hist(h)
binning = zfit.binned.RegularBinning(120, 60, 120, name="mass")
space = zfit.Space("mass", binning=binning)
background = zfit.Parameter("background", 0)
mu = zfit.Parameter("mu", 91)
gamma = zfit.Parameter("gamma", 4)
unbinned_model = zfit.pdf.SumPDF(
[zfit.pdf.Uniform(60, 120, space), zfit.pdf.Cauchy(mu, gamma, space)], [background]
)
model = zfit.pdf.BinnedFromUnbinnedPDF(unbinned_model, space)
loss = zfit.loss.BinnedNLL(model, binned_data)
minimizer = zfit.minimize.Minuit()
result = minimizer.minimize(loss)
binned_data.to_hist().plot(density=1)
model.to_hist().plot(density=1);/home/runner/miniconda3/envs/skhep-tutorial/lib/python3.12/site-packages/zfit/__init__.py:93: UserWarning: TensorFlow warnings are by default suppressed by zfit. In order to show them, set the environment variable ZFIT_DISABLE_TF_WARNINGS=0. In order to suppress the TensorFlow warnings AND this warning, set ZFIT_DISABLE_TF_WARNINGS=1.
warnings.warn(